August 05, 2014
这篇博客做的工作非常impressive,我花了陆陆续续大概一周之间将它翻译成中文。作者是比利时根特大学毕业,博士期间一直在做music information retrieval的工作,现在他是Deepmind的一名研究科学家。
前言
今年夏天,我在纽约Spotify实习,我的实习工作是使用卷积神经网络基于音乐内容做音乐推荐,在这篇博客中,我会解释我的方法和展示一些初步的结果。
Overview
这篇博客很长,这里提供一个博客各个部分的一些概览。如果你想跳过一些部分,直接在下面选择章节标题就可以到达。
-
非常简单的介绍一下协同过滤的优缺点
-
当没有可用的数据时该如何做?
-
基于音乐音频信号的音乐推荐
-
我在Spotify训练的网络细节
-
当使用很多音乐音频样本来训练卷积神经网络时,它学到了什么有关于音乐的东西?
-
潜在的应用
Collaborative filtering
Spotify传统的音乐推荐非常依赖于协同过滤算法来提升推荐准确度。协同过滤的主要思想是从用户的历史行为数据决定用户的偏好。比如说,如果两个用户听了大量相同的歌曲,那么这两位用户的音乐品味可能是相似的,如果两首歌被相同的用户群体听过,那么这两首歌听起来也是相似的。这种信息能够用来做推荐
纯粹的协同过滤方法不使用任何和被推荐物品内容有关的信息,只使用和被推荐物品有关的消费行为信息,换句话说,这些信息是与被推荐物品内容无关的。这使得这种方法能够被广泛使用:同样的模型能够被用来推荐书,电影,音乐等。
不幸的是,这种方法也被证明有很大的缺陷。由于这种方法非常依赖于用户的行为数据,越流行的物品比不那么流行的物品会被更加容易被推荐,因为对于流行的物品来说,有更多的可用的用户行为数据。这个问题通常不是我们想遇到的。同样出于这个原因,推荐的物品可能让用户觉得无聊和重复的。
这种方法存在另外一个问题在因为推荐上尤为明显。那就是有着相似用户行为的物品往往内容却非常不相同(the heterogeneity of content with similar usage patterns)。比如说,用户可能一次收听一整张专辑,但是一张专辑也许包括intro tracks,outro tracks,interludes,cover songs,remixes。
但是最大的问题是新的和不流行的歌曲不能够被推荐,如果没有可用的用户行为数据分析,那么协同过滤算法就会失效。这也就是所谓的冷启动问题(cold-start problem ). 我们想要能够推荐刚刚发布的音乐作品,我们想要给用户推荐他们不知道的非常棒的乐队,想要完成这个目标,我们需要用不同的方法!
Content-based recommendation
最近,Spotify饶有兴趣地想要整合其他信息源进入他们的推荐系统当中达缓解一些上述问题。这也被Spotify几个月前收购了音乐智能平台The Echo Nest所证明,有非常多不同种类和音乐相关的信息可以被推荐系统利用:tags,歌手和专辑信息,歌词,从web端挖掘的文本信息,甚至是音频信号本身。
对于以上的所有信息,大概音频信号本身是最难有效使用的,一方面music audio之间有巨大的语义鸿沟,另一方面,音乐的不同方面都会影响用户的偏好。一些信息能够很容易从音频信号中提取出来,比方说音乐的流派和所使用的乐器。其它的就有点困难,比如说音乐的情感,发行的年份,还有一些是不可能从音频本身提取出来的,比如说歌手的地理位置和歌词主题。
抛开以上这些难点,很明显的是歌曲本身很大程度上会决定用户是否喜欢听这首歌,所以通过分析音频信号来预测一首歌是否会被喜欢是一个很好的idea。
predicting listening preference with deep learning
在去年12月,我的同事Aaron van den Oord 和我在NIPS 2013上发了一篇这个主题的文章,名字就是”Deep content-based music recommendation“. 我们想要从音频信号本身来预测用户偏好,通过训练一个回归模型来预测一个之前使用协同过滤算法计算的潜在表征。这种方法能够让我们即使没有用户行为数据,也能够在协同过滤空间里面预测一个表征。你能够从我们的论文题目中推断出来了,这个回归模型就是一个深度神经网络。
这种方法的根本思想就是许多协同过滤模型把用户和歌曲都投影到一个共同的低维潜在因子空间。这首歌在这个空间里的位置由各种各样能够影响用户偏好的的信息编码。如果两首歌在这个空间里靠得很近,那么他们大概率是相似的,如果一首歌很靠近一个用户,那么这首歌对这个用户可能是一个很好的推荐(假如他们从来没有听过)。如果我们能够从音频来预测这首歌曲在这个空间里的位置,那么就能在没有用户行为数据的情况下将歌曲推荐给正确的用户。
在论文中我们使用t-SNE算法将模型预测的表征投影到低维空间。下面你可以看到结果图,相似的歌曲聚集在一起。Rap music 大部分能够在图的左上角找到,电音歌手则聚集在图的底部。

Scaling up
论文中深度神经网络包括两层卷积层和两层全连接层,网络的输入时三秒的音频的频谱,为了获得更长音频的表征,我们将音频加上一个三秒的窗,取这些窗的平均的预测表征。
在Spotify,我能够接触到更大数据集,一堆不同协同过滤算法计算出来得laten factor representations,他们也给了我一个很好的GPU来训练模型,这能够使得我拓展之前的工作,现在我能够训练有七层或者八层的卷积神经网络,使用大得多的中间表征和更多的参数(应该是指更复杂的卷积层)。
Architecture
下面我会详细介绍尝试过的一个网络结构,它有四个卷积层和三个全连接层。正如你会看到的,用于音频信号的卷积神经网络和传统的应用于计算机视觉任务的网络有一些重要的不同。
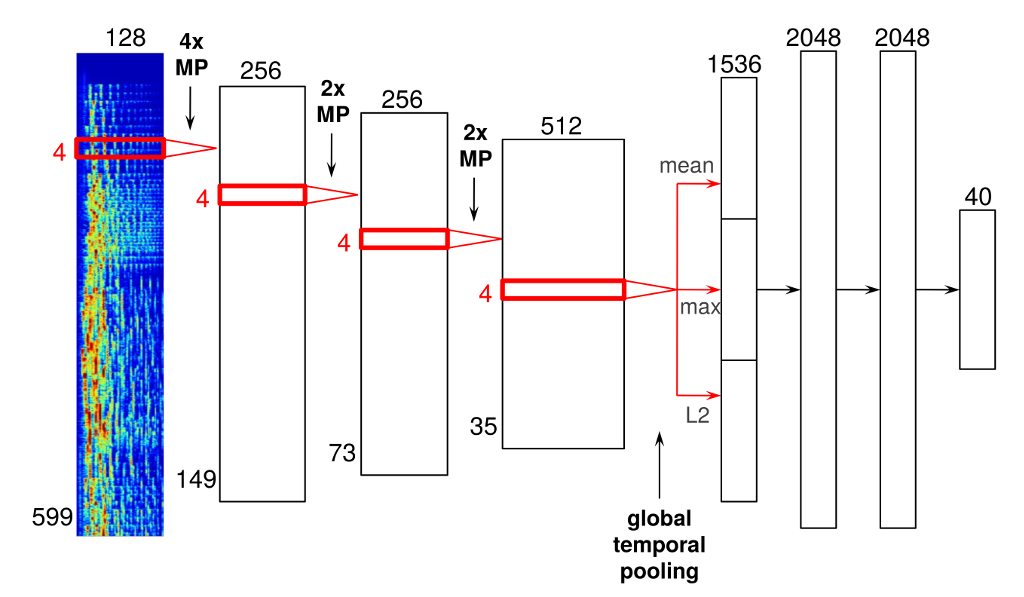
这个网络的输入是599帧长和128个mel bins的梅尔频谱,梅尔频谱是一种时频域上的表征,在音频信号上用重叠的窗口做短时傅里叶变换,每一个傅里叶变换产生一帧,然后把这些帧concatenate成一个矩阵就构成了一张频谱,最后对这张频谱转换成梅尔频谱减少维度,幅度上也发生了对数转换。
卷积层上红色矩形就是卷积核在它们的输入上滑动,使用rectified linear units(ReLU,max(0,x))。注意所有层都是一维卷积,这种卷积只在时间维度上进行卷积,而不是在频域上卷积。尽管在频谱上的时域和频域两个维度上卷积在方法上是可行的,当前我不会这么做。因为频谱上的两个维度有不同的含义,这和图片的例子不同。因此使用经常用在图片上的二维卷积核这是不合理的。
在卷积层之间使用max-pooing对中间层的表征downsample,为他们增加一些时间不变性,在图中用MP标记。我在每一个卷积层上使用4帧大小的的卷积核,出于performance的原因,我在第一二个卷积层之间使用4大小的max-pooling,其它层之间都使用2大小的池化。
在最后一层卷积层后,我在时间维度上使用全局池化层,这一层能覆盖到整个时间轴,有效地计算在时域上学到的特征,我一共使用了三个池化函数:平均池化,最大值池化,L2正则。
我这么做的原因是在音频信号中检测到特征的绝对位置和当前的任务尤其不相关。这和图片分类不同,在一张图片中,知道一个被检测到特定特征的大概位置是有用的,比如说,一个判断云的特征更可能在一张图片的顶端被激活,如果它在图片的底部被激活,也许它是检测到了一只羊。对于音乐推荐来说,我们只对音乐中一些特征整体上出现了还是没有出现感兴趣,所以在时域上做全局池化是非常合理的。
另外一个解决这个问题的方法是像我们NIPS那篇文章一样,在短的音频片段上训练一个神经网络,然后在更长的音频片段上加窗,将每一个窗口的值平均作为特征。然而,将池化整合到网络模型中似乎是一个更好的idea,因为在训练的时候,每一步池化都能够发生。
这个全局的池化特征然后作为一组带relu激活函数全连接层的输入,在这个网络中,网络的最后一层是作为输出层,用来预测40个由vector_exp算法计算的潜在因子,这个算法是曾经在Spotify所用到的众多协同过滤算法之一。
training
训练网络优化的是从协同过滤算法得出潜在因子表征和我们网络从音频信号预测的表征之间的mean square error(MSE),这些从协同过滤算法得到的表征做了归一化处理,这么做可以减少歌曲流行度的影响(对于很多协同过滤算法模型计算得到的表征往往和歌曲流行度有关)。Dropout在全连接层后用来正则化。
当前我用的数据集是从100万首流行音乐中间提取的30秒片段,计算出梅尔频谱,我大概用了这数据集的一半(50万)来训练,5000首用来验证,剩下的用来做测试集。在训练的时候,我们使用随机偏移值对频谱进行了修剪达到数据增强的目的。
这个神经网络使用Theano来搭建,在英伟达GTX 780Ti上使用mini batch梯度下降来优化loss,训练数据加载和数据增强分开实施,也就是说GPU在训练一个batch数据时,下一个batch的数据也在并行加载,总共进行了大约750000次梯度更新。我不记得整个网络大约花了多久训练,所有的步骤大概花了18-36小时
Variations
正如我前面提到的,这只是我尝试过的其中一个网络结构,我还尝试了一些别的方法。
- 更多层
- 使用maxout units作为激活函数,而不是用relu
- 使用随机池化而不是最大值池化
- 将L2正则整合到网络的输出层
- 数据增强在时域上使用了拉伸或者压缩频谱
- 将不同协同过滤算法得到的不同表征concatenate
还有一些方法没有达到我的预期
- 从卷积层增加’bypass‘连接到全连接层,(我觉得这有点像ResNet的思想,考虑到这还是14年,作者就已经很超前了),当然作者这里这么做的motivation是他认为底层特征也能够对音乐推荐有作用,但是不幸的是,这种设置非常阻碍训练(可能还是当时的计算能力有限)。
- 想mixture density networks一样预测一个表征的条件方差,然后获得一个对预测表征的置信估计,确定哪首歌的潜在因子表征是困难的。然而这会使得训练非常的困难,并且结果的置信度估计不如预期表现得好。
Analysis:what is it learning?
接下来就是本篇博客的spotlight部分了,打起精神!!
现在是非常cool的部分了,卷积神经网络学到了什么?这些特征看起来像什么?我使用卷积神经网络来解决这个问题的主要原因是我相信基于音乐内容的推荐是一个包含了多个抽象层面的问题。我希望神经网络的连续层可以递进地学习到更复杂和不变的特征,就像他们在图像分类问题上那样。
结果就如我所设想的那样,首先,让我们看下第一个卷积层,这里有很多卷积核直接作用在输入的频谱上,这些卷积核很容易可视化,可视化结果如下图,点击这张图可以看到更清晰的版本(5584*562)。负值是红色的,正值是蓝色的,白色的是0.注意每个卷积核只有四帧宽,单个卷积核使用黑红色的线分开。

图注:第一层卷积层学到的特征的可视化,时间轴是水平的,频率轴是垂直的,频率从上至下增加
从这张表征图,我们能够看到很多卷积核能够学习到和声内容,这些内容在不容频率区域以并列的红色和蓝色带显示。有时候这些带是倾斜向上或向下,表明音调的上升或者下降,这表明这些卷积核能够检测人的歌声。
Playlists for low-level features: maximal activation
为了能够更好的理解这些卷积核学到的东西,我从测试集上中选择了一些能够最大激活这些卷积核的歌曲制作了一个清单,下面是一些例歌,第一层有256个卷积核,我用0-255随机的标上序号,这些序号是无序的。
这些歌曲清单包括那些被分析的歌曲,这些30秒的歌曲能够最大地激活一个给定的卷积核。我从第一个卷积层中选择了一些有趣的卷积核,并且计算他们学到的表征,然后在筛选出在整个测试集上最大的激活。注意你应该听歌曲的中间部分来听这些卷积核从中学到了什么,因为这一部分的音频内容被选中分析。
下面每个spotify播放清单都有十首歌曲,他们中的一些因为版权问题可能不是在所有国家都能听。
这些歌曲的清单我没有设置了,大家想听的话可以去这篇博客原来的地方听
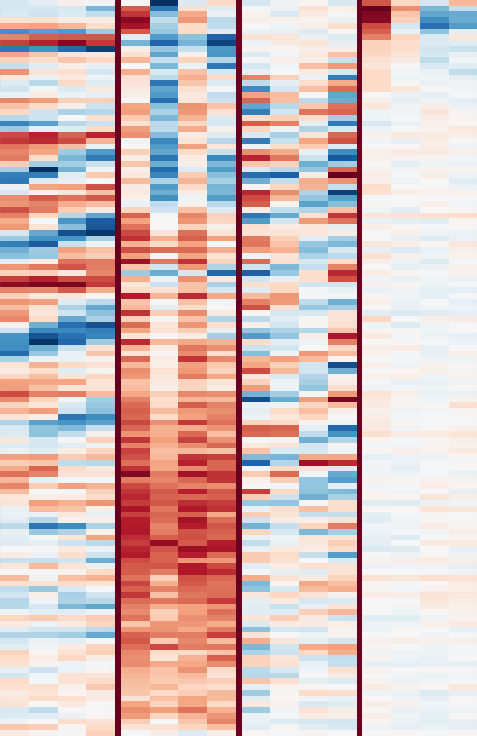
图注:卷积核14,242,250,253的表征特写
- 卷积核14似乎检测到了唱歌中的颤音技巧
- 卷积核242似乎检测到了铃声
- 卷积核250似乎检测到了vocal thirds, 就是多个歌手在唱同一个内容时,但是音符相差 一个major third(4个半音)
- 卷积核253似乎能够检测不容种类的bass和drum的声音
这几类播放清单里面的歌曲流派相差很不同,这表明这些卷积核能够学习到一些底层音频信号属性。
Playlists for low-level features: average activation
下面的四个播放清单的获得有一点点不同:我计算了每个卷积核对每首歌曲在时间上的平均表征,然后选择这些平均值里最大的。这意味着对于这些播放清单,卷积核被三十秒长的歌曲持续激活,这种设置对检测和声模式(harmonic pattern)非常有用。
这些歌曲的清单我没有设置了,大家想听的话可以去这篇博客原来的地方听
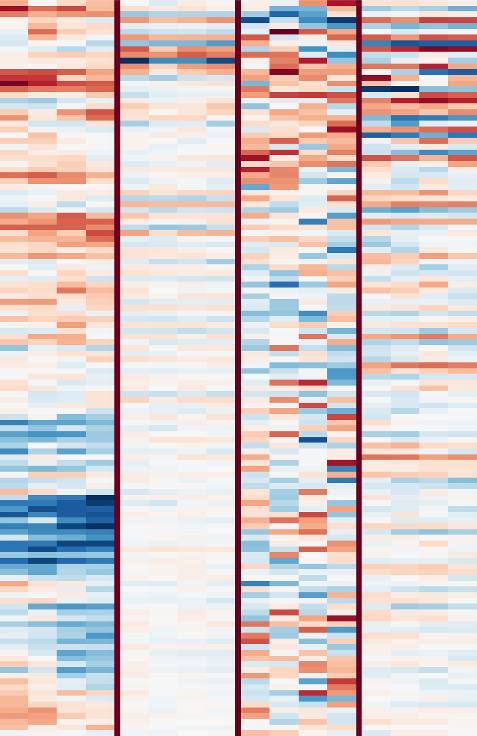
图注:卷积核1,2,4,28的表征特写
- 卷积核1 能够检测noise和guitar distortion
- 卷积核2 能够检测一个特定的音调:low Bb, 似乎有时候他也能够检测低了一个半音的A,因为梅尔频谱的频率分辨率不足以区分这两个音调。
- 卷积核4能够检测不同低音的嗡嗡嗡声音
- 卷积核28能够检测A和弦,似乎能够检测minor和major两种,所以它也许能够检测A和E调
我认为非常神奇的是神经网络能够学习检测特定的音调和和弦,我之前认为一首歌曲中特定的音调和和弦并不会真正的影响用户的偏好(注意作者这里的监督标签是协同过滤算法计算出的表征)。我对这个现象有两个假设。
- 这个网络学会的检测harmonicity,通过不同的卷积核检测不同种类的harmonic,然后将这些在更高层聚合起来检测不同音调的harmonicity。
- 这个网络能够学习某个流派中比其它流派中更加常见的和弦和和弦进程。
我没有去验证这两种假设,但是似乎后者对网络来说更加困难,所以我认为前者更有可能。
Playlists for high-level features
网络中的每一层都将底层作为输入,然后从中提取出更高层的特征,在顶端的全连接层,也就是输出层之前,这些卷积核对某些子流派歌曲非常具有选择性,可视化这些卷积核在频谱层面学到了什么不是很麻烦,以下的六个播放清单是能够最大激活这些高层卷积核的歌曲。
这些歌曲的清单我没有设置了,大家想听的话可以去这篇博客原来的地方听
很明显的是,每个卷积核能够识别特定的流派,有趣的是一些卷积核,比如说卷积核15似乎是一个多模态的卷积核,它能够被多种风格的音乐激活,这些风格的音乐之间完全没有联系。想必这个卷积核的输出当组合其它卷积核的输出时是非常确定的。
卷积核37非常有趣,似乎它能识别中文语言,这并非完全不可能,因为中文的音素库和其它语言完全不同,还有一些其它检测语言的卷积核:有一个卷积核能够检测西班牙语唱的rap music。另外一种可能是话语流行音乐有一些和其它音乐截然不同的特点,而这个模型能够检测到。
我花了一些时间分析前50个卷积核,一些其它的卷积核能够检测lounge,reggae,darkwave,country,metalcore,salsa,Dutch,German carnival music,儿歌,舞曲,vocal trance,朋克,土耳其流行音乐,还有我的最爱”Armin van Buuren”,显然他有非常多的歌曲以至于他能够有自己的卷积核。
AlexNet已经在许多其它计算机视觉任务上取得巨大成功,基于它的多样性和不变性,似乎这些卷积核除了应用在音乐推荐上预测潜在因子,还能够应用在其它音乐信息检索任务上。
Similar-based Playlists
预测的潜在因子能够用来找到相似的歌曲下面是一组清单中的歌是通过预测一首给定歌曲的潜在因子,然后在测试集中找到其它歌曲的潜在因子和这首歌曲的余弦距离相近的歌曲,下面每个清单中的第一首歌就是这首查询歌曲。
这些歌曲的清单我没有设置了,大家想听的话可以去这篇博客原来的地方听
大多数相似的歌曲对这首查询歌曲的粉丝都是正常的推荐,当然这些清单里的推荐歌曲远远称不上完美。但是考虑到他们仅仅是基于音频信号本身计算出来的,这个结果已经相当可以了。有一个错误的推荐是清单中由John Coltrane唱的”My Favorite Things”, 这首歌的特征出现了几个异常值,Elvis Presley唱的”Crawfish”也是同样如此。这大概因为歌曲在8:40-9:10部分出现了一段非常crazy的萨克斯独奏。分析整首歌或许会得到更好的推荐结果。
What will this be used for?
Spotify已经使用了很多不同的信息源和算法加入他们的推荐系统当中,所以我的工作最明显的应用是简单的将它作为一个额外的信息。然而它也能够用来过滤其它推荐算法得到的结果。就如我前面提到的,协同过滤算法往往推荐的歌曲汇总包括intro traks, outro tracks, cover tracks,和remixs,这能够使用基于内容的方法有效地过滤。
我的方法一个最主要的目标是尽可能地推荐一些新的歌曲和不流行的歌曲,我希望这能够帮助到一些不为人知歌手和将要发行的音乐作品。通过使Spotify能够向合适的观众推荐他们的音乐,它将在一定的程度上提供一个公平竞争的环境。
非常欣慰的是,这工作中的一部分将准备A/B测试,所以我们能够在实际中发现基于音频的推荐将有所不同,这也是我非常欣慰的事情,这在学校可不是轻松能够做到的事情。
Fueture work
其它的Spotify收集的用户反馈是对广播电台上播放的曲目点赞或者点灭。这也是一类极其有用的信息能够决定歌曲是否相似。不幸的是他们同是也是非常noise的,当前我在learning to rank情景下使用这类数据。我也想使用不同的距离衡量学习算法,比如说Drlim。如果我想出了什么好的想法我也许会写另外一篇博客。
Conclusion
在这篇博客当中,我总结了我至今为止在Spotify担任机器学习实习生的工作,我介绍了我使用卷积神经网络来做基于音频的音乐推荐,我也给出了一些insight: 神经网络实际上学到了什么。这种方法更多的细节请参照NIPS 2013年论文”Deep content-based music recommendation“
如果你对深度学习,特征学习,和它们在音乐上的应用感兴趣,你可以看看我的reseach page,那里有我在这个领域做的一些其它工作的总结。如果你对Spotify的音乐推荐方法感兴趣,请参考这写presentation或者Erik Bernhardsson的博客
Spotify是一个非常适合工作的地方。这里非常崇尚技术的开源(至少他们让我写了这篇博客),这在别的公司通常是不会允许这么做的。如果你对推荐系统,协同过滤,音乐信息检索,或者你正在寻找实习或者永久职位,马上联系他们吧。
如果你对这篇博客有任何问题,请随时到一下社区给我留言。
- Post on Hacker News
- Post on r/machinelearning(失效)
- Post on the Google+deep learning community(失效)
- Post on the Google+music information retrieval community(失效)