1.声谱图
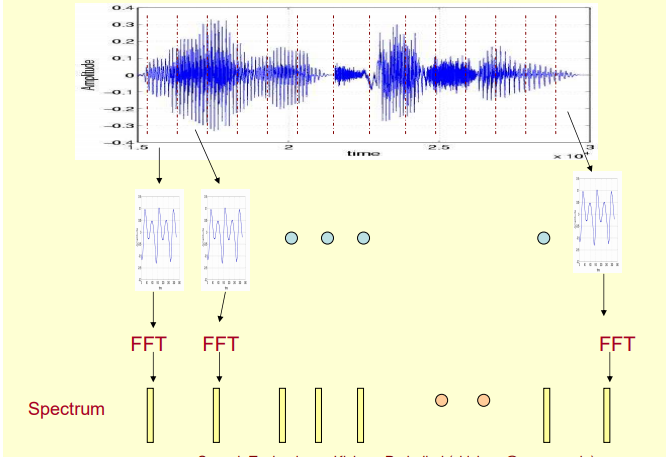
如下图1一段声音信号直观地看起来是时间和能量的关系,在语音识别,音乐信息检索中常常关注的是声音中频率和能量的关系,即声谱图描述的就是频率和能量的关系。所以我们拿到一段音频需要先进行初步的处理,获得它的声谱图。具体的做法则是将声音信号分帧,然后对每一帧都用短时傅里叶变换处理,当然进行傅里叶变换之前还预先需要对声音信号进行预加重,加窗。
2.梅尔频谱
由于人耳对声音的感知不是线性的,人耳对声音的低频比对声音的高频更加敏感。所以常常需要将线性频谱转换到非线性的梅尔频谱。普通频率转换到梅尔频率的公式是
我们将一组频域信号通过梅尔滤波器组就可以获得梅尔频谱。
总结一下获得梅尔频谱的大概流程:首先对时域信号进行傅里叶变换转换到频域,然后再利用梅尔频率刻度的滤波器组对应频域信号进行处理,就可以得到梅尔频谱。这个流程可以使用librosa库来完成,下面就是相应的代码。
1 | import librosa |
reference
以下这两篇博客将梅尔频率倒谱系数(MFCC)讲得很清楚,推荐!求MFCC需要在梅尔频谱的基础上继续取对数再进行变换。这次我只是把梅尔频谱当做神经网络的输入,就先到这里。